RateLimiter
创建
```java
double batchDataRate = 20 //每秒可获取的许可数,及可操作数
RateLimiter batchRateLimiter = RateLimiter.create(batchSlowDataRate)
```java概念
1. RateLimiter 速率限制器,会在可配置的速率下分配许可证。如果必要的话,每个acquire() 会阻塞当前线程直到许可证可用后获取该许可证。一旦获取到许可证,不需要再释放许可证。
2. RateLimiter使用的是一种叫令牌桶的流控算法,RateLimiter会按照一定的频率往桶里扔令牌。 acquire() 与 acquire(size)
1. acquire()是针对每一条任务来获取许可的,每秒可获取的许可数取决于创建时给定数量。(通过控制每秒任务条数来达到限速)
2. acquire(size)是针对于某一类任务来获取,即这批任务每秒内获取size个许可来干活。(通过限制每秒任务速率来达到限速)项目中实际使用
我的需求是将大批量的任务放缓速度来执行,从而达到短时间内对DB的压力
前提是可以接受短时间的延迟多线程
线程池 ThreadPoolExecutor
创建及参数
ExecutorService executor = new ThreadPoolExecutor(0, 100, 10, TimeUnit.SECONDS, new ArrayBlockingQueue(100), new ThreadFactoryBuilder().setNameFormat(“demo-%d”).build()); 参数 类型 代表 corePoolSize int 核心线程池大小 maximumPoolSize int 最大线程池大小 keepAliveTime long 线程最大空闲时间 unit TimeUnit 时间单位 workQueue BlockingQueue 线程等待队列 threadFactory ThreadFactory 线程创建工厂 handler RejectedExecutionHandler 拒绝策略
Java8 集合 Stream的使用
Lambda
- 基本使用实例
- () -> result 不需要参数,直接返回result
- x -> 2 * x 接收一个参数返回其2倍
- (x,y) -> x - y 接收两个参数并返回差值
list.stream.fiflter
基本使用
准备一个实例 EmployPojopublic class EmployPojo { private String name; private String age; private String address; } ```java 具体使用: ```java public static void main(String[] args) { List<EmployPojo> pojos = Lists.newArrayList(); pojos.add(EmployPojo.builder().name("dong").age("25").address("china").build()); pojos.add(EmployPojo.builder().name("xiao").age("26").address("china").build()); pojos.add(EmployPojo.builder().name("hua").age("27").address("china").build()); pojos.add(EmployPojo.builder().name("hua").age("3").address("china").build()); pojos.add(EmployPojo.builder().name("dongxiaohua").age("28").address("china").build()); List<String> argList = Lists.newArrayList("25", "9", "10"); /** * 将符合表达式的第一个对象返回 * Optional<EmployPojo> employPojo * employPojo.orElse(null); */ Optional<EmployPojo> employPojo = pojos.stream().filter(pojo -> argList.contains(pojo.getAge())).findFirst(); // 将符合表达式的所有对象返回 List<EmployPojo> employPojos = pojos.stream().filter(pojo -> (argList.contains(pojo.getAge()) || "28".equals(pojo.getAge()))).collect(Collectors.toList()); // 将符合表达式的所有对象只能够的指定字段返回 List<String> names = pojos.stream().filter(pojo -> argList.contains(pojo.getAge())).map(EmployPojo::getName).collect(Collectors.toList()); /** * 将list按照指定字段作为key,value转换成map * 其中(k1,k2)-> k2 表示当key重复的时候选择后者覆盖前者,或者例如下给定重新值 */ Map<String, String> map = pojos.stream().collect( Collectors.toMap(EmployPojo::getName, EmployPojo::getAge, (k1, k2) -> String.valueOf((Integer.valueOf(k1) + Integer.valueOf(k2))))); } ```java
详解
JVM虚拟机
jvm虚拟机内存模型图
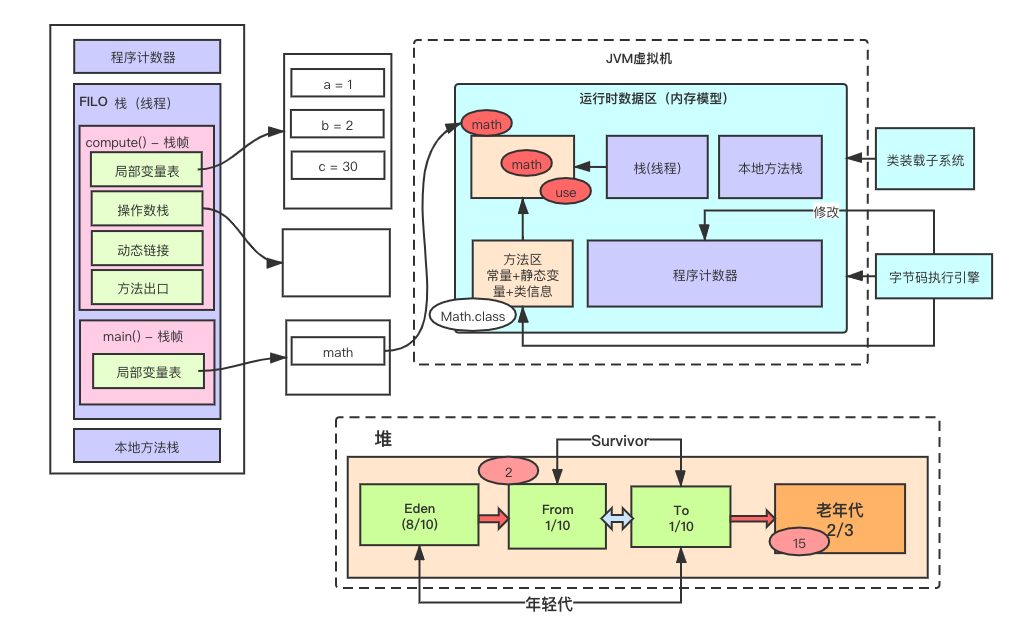
JVM虚拟机组成
- 类装载子系统
- 运行时数据区(内存模型)
- 字节码执行引擎
运行时数据区(内存模型)
* 栈(线程栈)
1. 每一个执行线程执行时,会分配一块儿线程专属栈内存区域,用来存储此线程执行过程中用到的局部变量
* 栈帧
1. 即线程专属栈内存区域中,为不同方法提供的专属内存区域存放此方法的局部变量。(一个方法对应一块儿栈帧内存区域)
2. 与数据结构中的栈的特点一致:First In,Last Out(先进后出)
3. 栈帧包括:
1. 局部变量表
存放方法的局部变量
2. 操作数栈
存放一些临时的操作数的内存区域
javap -c xx.class 来查看jvm指令码
操作数栈是为了存放jvm指令码,将指定变量的值装载出来,并在局部变量表中创建一块区域,将指定的(装载出来的)变量放入局部变量表。<插播程序计数器>
3. 动态链接
4. 方法出口
在main方法中调用其它方法时,已经在栈帧内的一块儿内存区域记录了被调方法执行完后要回到main方法的什么位置。
4. 堆与栈的关系:栈中存放了无数堆中对象的指针(内存地址)
* 本地方法栈
1. 本地方法
native 关键词修饰
跨源调用一般用本地方法
2. 本地方法栈则是在调用本地方法时,本地方法需要的一块儿内存区域
* 方法区(共用变量)
1. 常量
2. 静态变量(或成员变量)
当静态变量为对象(new出来),则在方法区中存的是堆中对象的指针(内存地址)
3. 类信息(比如栈中用到的字节码信息)
* 程序计数器(是每个线程独有的)作用是为了在多线程切换的时候知道从哪个位置继续执行。
1. 记录当前线程正在运行的那一行jvm指令码的行号位置。(由字节码执行引擎记录)
* 堆
-- jvisualvm 调出VisualVM
1. 年轻代(默认占2/3堆内存)
1. Eden(伊甸园区)(默认占8/10的年轻代内存)
存放新new出来的对象
- minor gc
1. 当新对象占满伊甸园区时,字节码执行引擎后台专门开启的一个线程来执行gc(清理垃圾对象)。
2. 通过可达性算法找出非垃圾对象后,通过复制算法将对象移到From(此时,这些对象的分代年龄+1),剩余在伊甸园区的垃圾对象一次性清理。
2. Survivor区
From区和To区是minor gc相互交替存放非垃圾对象。
- From(默认占8/10 年轻代内存)
1. 存放第一次minor gc的复制算法复制过来的非垃圾对象(此时的分代年龄已经+1)
2. 伊甸园区第二次minor gc的时候,From区也会执行minor gc,此时通过可达性分析算法找出From区中非垃圾对象复制到To(分代年龄+1),然后将From中垃圾对象一次性清理。
- To(默认占8/10 年轻代内存)
1. 当此区内存在非垃圾对象后,伊甸园区再次执行minor gc时,To区也会执行,只是通过可达性算法找出的将】非垃圾对象复制到From区(分代年龄+1),并清理垃圾对象。
2. 老年代(默认占2/3堆内存)
当对象的分代年龄达到15时,会将对象放到老年代。(即一直存活的对象:对象类型的静态变量,线程池内对象,缓存,Spring Bean容器的对象)
当老年代被放满时会执行full gc
- full gc
1. 会尝试的去收集整个堆的垃圾对象
2. 当老年代收集不出任何垃圾对象,那么下次有对象再复制到老年代时则会OOM(内存溢出)Elasticsearch 7.x 修改分词
Elasticsearch(7.x)
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/index.html
elastic 默认分词器
template,index的创建以及分词修改
PUT _template
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36PUT /_template/my_test
{
"template": "my_test-*",
"order": 1,
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "1",
"store": {
"type": "niofs"
}
}
},
"mappings": {
"_source": {
"enabled": "true"
},
"dynamic_templates": [
{
"stringType": {
"mapping": {
"type": "keyword"
},
"match_mapping_type": "string"
}
}
],
"properties":{
"name": {
"analyzer": "ik_max_word", //指定分词
"type": "text"
}
}
},
"aliases": {} //设置别名
}PUT index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43PUT /my_test-1
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "1",
"store": {
"type": "niofs"
}
}
},
"mappings": {
"_source": {
"includes": [
"name" //指定索引文本字段
]
},
"dynamic_templates": [
{
"stringType": {
"match_mapping_type": "string",
"mapping": {
"index": false,
"store": false,
"type": "keyword"
}
}
}
],
"properties": {
"name": {
"type": "text",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
},
"analyzer": "ik_max_word" //指定分词
}
}
}
}给指定index添加新的分词(ngram)
- 首先将分词加入setting中,修改是需要将index 关闭
1
2POST my_test-2/_close
POST my_test-2/_open - 添加分词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23PUT /my_test-1/_settings
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
将索引中指定字段使用新增加的分词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15PUT my_test-2/_mapping/
{
"properties": {
"name": {
"type": "text",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
},
"analyzer": "ngram_analyzer"
}
}
}PUT doc
1
2
3
4PUT my_test-1/_doc/[id]?routing=[my_test_data-1]
{
"name": ""
}GET search
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19GET my_test-2/_search
{
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "",
"minimum_should_match": "-25%",
"boost": 2
}
}
}
]
}
}
}查看分词结果(ngram和ik——max_word分词)
1
2
3
4
5
6
7
8
9
10
11GET /my_test-1/_analyze
{
"tokenizer": "ngram",
"text":""
}
GET /my_test-2/_analyze
{
"analyzer": "ik_max_word",
"text": ""
}指定字段的子field,可以指定不同的分词机制,在search的时候可 name.field 来实现不同分词搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15PUT my_test-1/_mapping
{
"properties": {
"name": {
"type": "text",
"fields": {
"std": {
"type": "text",
"analyzer": "ngram_analyzer"
}
},
"analyzer": "ik_max_word"
}
}
}
小记
修改添加到source中的字段的mapping,可通过 POST my_index/_update_by_query?conflicts=proceed 来重新索引数据curl查询es
Authorization认证 Basic方式 后续编码属于 用户名:密码 用base64方式编码的结果
查看索引
curl -XGET -H’Authorization: Basic {basic.authentication}’ ‘http://{ip:port}/_cat/indices/{index_name}*’创建索引
curl -XPUT -H’Authorization: Basic {basic.authentication}’ ‘http://{ip:port}/{index_name}’查模版
curl -XGET -H’Authorization: Basic {basic.authentication}’ ‘http://{ip:port}/_templates/{template_name}’
curl -XGET -H’Authorization: Basic {basic.authentication}’ ‘http://{ip:port}/_template/{template_name}?pretty’
Tomcat access日志
日志格式配置
位置在服务下 config/server.xml 中Host标签下:
1 | <Host name="localhost" appBase="webapps"unpackWARs="false" autoDeploy="false"> |
参数说明
| Key | Value |
|---|---|
| className | 官方文档:This MUST be set to org.apache.catalina.valves.AccessLogValve to use the default access log valve |
| directory | 日志文件存放的目录。通常设置为tomcat下已有的那个logs文件。 |
| prefix | 日志文件的名称前缀。 |
| suffix | 日志文件的名称后缀。 |
| pattern | 主要参数,见下文 |
| resolveHosts | 如果是true,tomcat会将这个服务器IP地址通过DNS转换为主机名;如果是false,就直接写服务器IP地址啦。默认false。 |
| rotatable | 默认为true,tomcat生成的文件名为prefix(前缀)+.+时间(一般是按天算)+.+suffix(后缀),如:localhost_access_log.2007-09-22.txt。设置为false的话,tomcat会忽略时间,不会生成新文件,文件名就是:localhost_access_log.txt。长此以往,这个日志文件会超级大 |
| condition | 这个参数不太实用,可设置任何值,比如设置成condition=”tkq”,那么只有当ServletRequest.getAttribute(“tkq”)为空的时候,该条日志才会被记录下来 |
| fileDateFormat | 时间格式,是针对日志文件名起作用的。咱们生成的日志文件全名:localhost_access_log.2016-09-22.txt,这里面的2016-09-22就是这么来的。如果想让tomcat每小时生成一个日志文件,也很简单,将这个值设置为:fileDateFormat=”yyyy-MM-dd.HH” |
pattern设置
1 | %a 这是记录访问者的IP,在日志里是127.0.0.1 |
awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
使用格式:awk ‘{pattern + action}’ {filenames}
- awk内置变量
1
2
3
4
5
6
7
8
9
10
11
12
13ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。
$NF是number finally,表示最后一列的信息,跟变量NF是有区别的,变量NF统计的是每行列的总数
- 按条件查询
awk ‘{if($13>3000){print $0}}’ |more -10 - 按时间查询:
awk ‘{split($4,array,”[“);if(array[2]>=”26/Sep/2019:17:40:00” && array[2]<=”26/Sep/2019:17:41:00”){print $0}}’ access.2019-09-26.log |more -10
HashMap原理
HashMap的工作原理
- HashMap的工作原理?(基于hashing,bucket中存储键值对)
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。 - 当两个对象的hashCode相同会发生什么?(hashCode()和equals()方法)
它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
注:首先,hashCode相同,但equals不一定相等,因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。 - 如果两个键的hashcode相同,如何获取值对象?(HashMap在链表中存储的是键值对)
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点。
使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。 - 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?(HashMap负载因子0.75)
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。 - 重新调整HashMap大小存在什么问题吗?(多线程的情况下,可能产生条件竞争(race condition))
如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。(多线程不适用HashMap) - 为什么String, Interger这样的wrapper类适合作为键
String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。 - 我们可以使用CocurrentHashMap来代替Hashtable吗?(Hashtable是synchronized的)
ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
HashCode与equals
- shCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的
- 如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同。
- 如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点。
- 两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里“。
Equals
- equals和==
==用于比较引用和比较基本数据类型时具有不同的功能:
比较基本数据类型,如果两个值相同,则结果为true
而在比较引用时,如果引用指向内存中的同一对象,结果为true;
equals()作为方法,实现对象的比较。由于==运算符不允许我们进行覆盖,也就是说它限制了我们的表达。因此我们复写equals()方法,达到比较对象内容是否相同的目的。而这些通过==运算符是做不到的。 - object类的equals()方法的比较规则为:
如果两个对象的类型一致,并且内容一致,则返回true,这些类有:
java.io.file,java.util.Date,java.lang.string,包装类(Integer,Double等)
String s1=new String(“abc”);
String s2=new String(“abc”);
System.out.println(s1==s2);
System.out.println(s1.equals(s2));
运行结果为false true
HashMap
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap的存取
根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
hash(int h)方法根据key的hashCode重新计算一次散列。此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
- 存储
当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。 - 读取
从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。- 总结:HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry
HashMap的resize
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过160.75=12的时候,就把数组的大小扩展为216=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.751000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
- 总结:HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry
总结
HashMap的实现原理:
利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
Mybatis的缓存机制及其作用的原理
Mybatis缓存机制
mybatis提供了缓存机制减轻数据库压力,提高数据库性能
mybatis的缓存分为两级:一级缓存、二级缓存
一级缓存是SqlSession级别的缓存,缓存的数据只在SqlSession内有效
二级缓存是mapper级别的缓存,同一个namespace公用这一个缓存,所以对SqlSession是共享的
一级缓存
mybatis的一级缓存是SqlSession级别的缓存,在操作数据库的时候需要先创建SqlSession会话对象,在对象中有一个HashMap用于存储缓存数据,此HashMap是当前会话对象私有的,别的SqlSession会话对象无法访问。
当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。(PerpetualCache)
- 具体流程:
- 第一次执行select完毕会将查到的数据写入SqlSession内的HashMap中缓存起来
- 第二次执行select会从缓存中查数据,如果select相同切传参数一样,那么就能从缓存中返回数据,不用去数据库了,从而提高了效率
- 注意:
- 如果SqlSession执行了DML操作(insert、update、delete),并commit了,那么mybatis就会清空当前SqlSession缓存中的所有缓存数据,这样可以保证缓存中的存的数据永远和数据库中一致,避免出现脏读
- 当一个SqlSession结束后那么他里面的一级缓存也就不存在了,mybatis默认是开启一级缓存,不需要配置
- mybatis的缓存是基于[namespace:sql语句:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的。例如:-1242243203:1146242777:winclpt.bean.userMapper.getUser:0:2147483647:select * from user where id=?:19
二级缓存
二级缓存是mapper级别的缓存,也就是同一个namespace的mappe.xml,当多个SqlSession使用同一个Mapper操作数据库的时候,得到的数据会缓存在同一个二级缓存区域
二级缓存它有数据的多session共享机制,但是呢,会导致user在两个命名空间下的数据不一致。
二级缓存默认是没有开启的。需要在setting全局参数中配置开启二级缓存。
- conf.xml:
1
2
3<settings>
<setting name="cacheEnabled" value="true"/>默认是false:关闭二级缓存
<settings> - mapper.xml这里配置了一个LRU缓存,并每隔60秒刷新,最大存储512个对象,而却返回的对象是只读的
1
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>当前mapper下所有语句开启二级缓存
若想禁用当前select语句的二级缓存,添加useCache=”false”修改如下:1
<select id="getCountByName" parameterType="java.util.Map" resultType="INTEGER" statementType="CALLABLE" useCache="false">
- 具体流程:
- 当一个sqlseesion执行了一次select后,在关闭此session的时候,会将查询结果缓存到二级缓存
- 当另一个sqlsession执行select时,首先会在他自己的一级缓存中找,如果没找到,就回去二级缓存中找,找到了就返回,就不用去数据库了,从而减少了数据库压力提高了性能